¿Cómo mapear un mensaje HL7 V2.X a FHIR?
Vermos como mapear un mensaje ORU HL7 versión 2.4 (técnicamente un ORU ^ R01 que contiene un resultado de radiología) y generar un mensaje FHIR que para enviar a un servidor FHIR, que luego guardará la Observación en su base de datos.
Para mantener las cosas razonablemente simples (aunque sean realistas), tendremos un solo segmento OBX con el resultado. En la práctica, es probable que tengamos varios segmentos OBX, cada uno de los cuales sería un recurso de observación separado en nuestro mensaje (más segmentos NTE y otros). Y tenga en cuenta que algunos de los segmentos no se utilizan; solo estamos sacando los datos que necesitamos para completar nuestro mensaje. Si estuviéramos planificando una transformación de '2 vías', es decir, manteniendo la capacidad de recrear el mensaje v2 del FHIR, entonces probablemente necesitaríamos capturar más datos, y probablemente también necesitemos algunas extensiones.
En esta publicación, vamos a considerar la creación del mensaje FHIR que contiene la observación de Radiología (y los recursos de apoyo); podemos considerar los aspectos de arquitectura y flujo de trabajo de procesar el mensaje posteriormente en otra publicación.
Y recuerde que HL7 v2 se puede usar de muchas maneras diferentes (si ha visto una implementación de v2 ...) por lo que este análisis es altamente específico para este caso de uso.
Aquí hay una muestra de cómo se vería el mensaje v2:
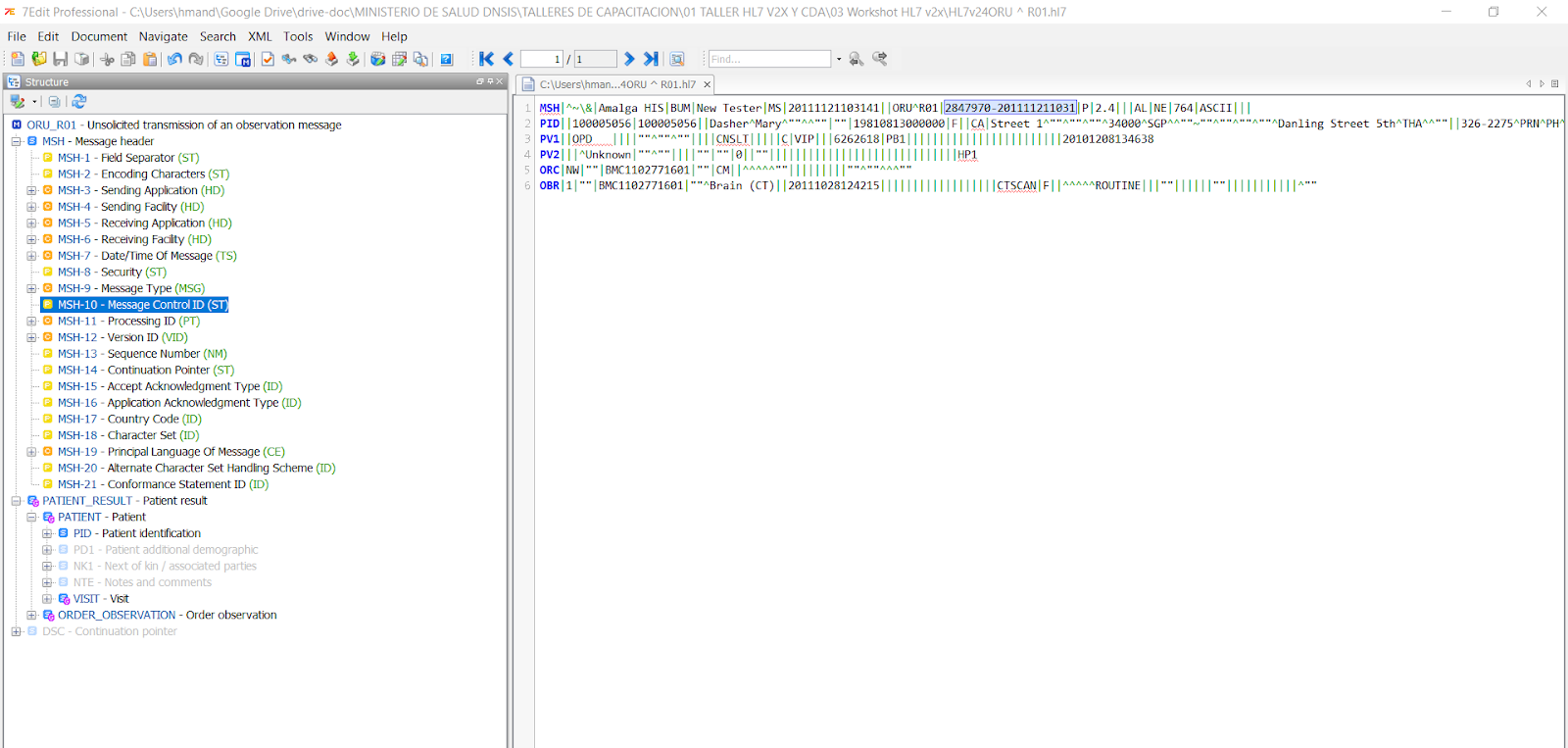
MSH|^~\&|Amalga HIS|BUM|New Tester|MS|20111121103141||ORU^R01|2847970-201111211031|P|2.4|||AL|NE|764|ASCII|||
PID||100005056|100005056||Dasher^Mary^""^^""|""|19810813000000|F||CA|Street 1^""^""^""^34000^SGP^^""~""^""^""^""^Danling Street 5th^THA^^""||326-2275^PRN^PH^^66^675~476-5059^ORN^CP^^66^359~-000-9999^ORN^FX^^66^222~^NET^X.400^a@a.a~^NET^X.400^dummy@hotmail.com|123456789^WPN^PH^^66|UNK|S|BUD||BP000111899|D99999^""||CA|Bangkok|||THA||THA|""|N
PV1||OPD ||||""^""^""||||CNSLT|||||C|VIP|||6262618|PB1||||||||||||||||||||||||20101208134638
PV2|||^Unknown|""^""||||""|""|0||""|||||||||||||||||||||||||||||HP1
ORC|NW|""|BMC1102771601|""|CM||^^^^^""|||||||||""^""^^^""
OBR|1|""|BMC1102771601|""^Brain (CT)||20111028124215||||||||||||||||||CTSCAN|F||^^^^^ROUTINE|||""||||||""|||||||||||^""
Dentro del 7Edit con el mapeo en arbol lo vemos asi:
Con mas detalle vemos los segmentos en el arbol

- MessageHeader
- Observation
- Patient (sujeto de la observación)
- Provider (es el que realiza la observación)
En el siguiente dibujo vemos como es la estructura de un bundle (empaquetado) de FHIR

Como base del análisis, haremos las asignaciones que están en la especificación FHIR (en la parte superior de cada página de recursos hay pestañas para el contenido, ejemplos, definiciones formales, asignaciones y perfiles)
Así que aquí es cómo podemos crear cada recurso, con algunas notas sobre las elecciones que debemos hacer.
Bundle
El Bundle o paquete es un conjunto de unidades atómicas (recursos), y el ID del paquete es un ID global único (por ejemplo, un UUID) que representa el mensaje FHIR como un todo. Esto es distinto de la ID de MessageHeader, que es importante cuando se trata de errores que ocurren durante la mensajería (consulte las especificaciones para una discusión sobre esto).
MessageHeader
Un mensaje FHIR es un paquete de recursos, con el recurso MessageHeader como primer recurso (y una etiqueta en el paquete). Hay una buena asignación entre MSH y MessageHeader:
| Element | V2 segment | Description |
| Identifier | MSH-10 | Message Control ID |
| Timestamp | MSH-7 | Message Date/time |
| Event | MSH-9.2 | observation-provideDerived from the second component of the Message Type field. Its value comes from HL7 table 3 |
| Source.name | MSH-3 | Sending application name |
| Source.software | MSH-3 | Sending application name |
| Source.endpoint | MSH-24 | Sending network address |
| Destination.name | MSH-5 | Receiving application |
| Destination.endpoint | MSH-25 | Receiving network address |
| data | References to the ‘root’ resource of the message. |
El identificador lo establece el sistema de envío y debe ser único en el contexto del remitente. Idealmente única globalmente, pero no hay garantía de eso desde el lado v2. Desde la perspectiva de FHIR, debe ser único dentro de "la corriente de mensajes"; en la práctica, esperamos que sea único en el contexto del remitente; después de todo, es la forma en que coincidirán los reconocimientos con el mensaje.
El elemento de software es un campo obligatorio, y la asignación en la especificación sugiere usar el segmento SFT. Sin embargo, eso solo se introdujo en la versión 2.5, así que duplicaremos el source.name aquí.
El código del evento se define en la especificación FHIR (hay una lista más completa aquí). Estos no son los mismos que los v2, aunque como la "fortaleza" de la vinculación es que podríamos usar los v2 si quisiéramos. Sin embargo, hay un valor que se adapta a esta implementación, proporcionar observación, así que lo usaremos.
Los elementos entrante, autor y receptor nos permiten especificar individuos (u organizaciones) a partir de quienes se originó el mensaje, o para quién es. No necesitamos eso aquí, pero es bueno saber que está disponible si es necesario.
En este caso, el elemento de datos será una referencia a la Observación. Si tuviéramos varias observaciones, probablemente incluiríamos un recurso de Lista para agruparlas. Y, por supuesto, un mensaje puede ser mucho más complicado que eso.
Observation
Este es el recurso que contiene lo que realmente queremos representar, en este caso un resultado de radiología, y la observación es uno de los recursos más flexibles en el FHIR estable.
Aquí está la tabla de resumen de mapeo:
| Element | V2 segment | comment |
| name | OBX-3 | |
| valueString | OBX-5 | OBX-5 holds the actual value of the observation |
| interpretation | OBX-8 | |
| comments | NTE-3 | See note below |
| appliesDateTime | OBX-14 | |
| issued | OBR.22 | |
| status | OBX-11 | Observation Result Status |
| reliability | OBR-25 | |
| identifier | OBX-21 | |
| subject | Reference to the Patient | |
| performer | Reference to the Practitioner |
El valor de la observación estará en el elemento Observation.value [x], donde [x] es uno de los tipos de datos FHIR especificados. En v2, hay al menos 3 campos que miraremos para decidir cómo obtener el valor.
OBX-2 es el tipo de Observación tal como se define en la tabla HL7 v2 0125. Para nuestro resultado de radiología, es probable que sea FT o ST y el tipo del elemento de valor [x] sea una cadena - haciendo el nombre completo del elemento valueString. Si estuviéramos construyendo un analizador genérico, entonces veríamos el valor de OBX-2 y lo usaríamos para decidir qué tipo de datos FHIR usar.
OBX-5 contiene el valor real de la observación. Los detalles de esto dependerán del tipo de datos como se discutió anteriormente, por supuesto ...
OBX-6 es las unidades del valor. No se aplica aquí, pero en muchas situaciones lo hará. Por ejemplo, si se tratara de una presión arterial sistólica, el tipo de datos sería Cantidad, que tiene un componente de unidades.
De acuerdo con la asignación en la especificación, cuando se emitió el informe, puede provenir de una serie de lugares diferentes, dependiendo de la fuente exacta y la naturaleza del mensaje. Iremos con OBR-22 (Fecha / hora de cambio de estado) para nuestro escenario.
La confiabilidad del resultado es un poco desafiante, y es un elemento obligatorio en el recurso de observación, por lo que no podemos ignorarlo. El mapeo en la especificación se refiere a OBX-8 (Banderas anómalas) y OBX-9 (Probabilidad), pero son más un reflejo del resultado dentro del rango esperado, en lugar de si el resultado puede ser confiable. OBR-25 (Estado del resultado) parece una mejor opción, así que iremos con eso.
Si hubo un comentario sobre el resultado, entonces se almacenará en un segmento NTE (o segmentos) separado inmediatamente después del OBX. No hay una referencia directa en v2 del OBX al NTE (o al revés); debe inferirse del hecho de que el NTE sigue al OBX.
También tenemos que pensar en lo que debe ser Observation.text, la narración legible para los humanos. Como se trata de un tipo de datos de cadena, y suponiendo que el tipo de datos v2 (OBX-2) era FT, incluiremos todo el valor en los elementos <pre> y tal vez agreguemos la fecha y los nombres de los autores allí también. Sospecho que una consideración adecuada de cómo generar narrativa es un tema completo en sí mismo, tal vez en otro momento.
Patient
En FHIR, el paciente es un recurso separado (tal vez ni siquiera en el mismo servidor que la observación), y la observación tendrá una referencia (como sujeto). Entonces, debemos encontrar al paciente en el servidor en el que esté almacenado y recuperar su url. También podríamos necesitar crear el paciente si no podemos encontrarlo, aunque esto dependerá de las políticas de la implementación, lo que podría requerir que el paciente exista primero.
La forma en que buscaremos un paciente utilizará el identificador del paciente del segmento PID. PID-3 tiene una lista de identificadores de pacientes que podemos usar, cada uno de los cuales es un tipo de datos CX, por lo que equivale al tipo de datos identificador FHIR. Necesitamos consultar el servidor del paciente para ver si el paciente ya existe, usando el identificador apropiado (basado en el espacio de nombres). Si existe, entonces tenemos la referencia. De lo contrario, podemos utilizar los datos en el segmento PID para crear un nuevo recurso para el paciente, si la política lo permite. Estos son los pasos:
Usando el identificador del mensaje v2, consulte el servidor FHIR de la siguiente manera:
GET [patientserver]/patient?identifier={identifier}
Si hay una coincidencia única, entonces tenemos la ID que podemos usar para el Observation.subject. (Y podemos colocar una copia del paciente dentro del paquete también)
Si hay más de una coincidencia, probablemente sea un error y deberíamos rechazar el mensaje o recibir intervención humana (nuevamente, habrá una política al respecto).
Si no hay coincidencias, el siguiente paso depende de si la tienda del paciente está en el mismo servidor que la observación.
Si es así, cree un nuevo recurso para el paciente utilizando los datos del segmento PID y asígnele un ID con un prefijo cid: (que le indicará al servidor que es un nuevo recurso para el paciente y lo guardará localmente, resolviendo la referencia a la Observación como lo hace).
Si el paciente está en un servidor separado, entonces necesitamos crear y guardar un paciente ahora, obteniendo una identificación del servidor a medida que se guarda. Luego podemos ubicar el recurso del paciente en el mensaje (junto con la ID correcta). Por supuesto, aquí hay preocupaciones transaccionales: ¿qué ocurre si salvamos al paciente, pero el resto del procesamiento del mensaje falla? Bueno, realmente no importa; la próxima vez que aparezca un mensaje con este identificador de paciente, encontraremos el que acabamos de crear, para que no se haga daño.
Tenga en cuenta que es posible descargar toda esta búsqueda al servidor utilizando la función de búsqueda interna de una transacción (hablamos de eso aquí), pero no estoy seguro de que la funcionalidad se aplique al procesamiento de mensajes y, en cualquier caso, no podemos Supongamos que todos los servidores tendrán esa funcionalidad, por lo que lo haremos por mucho.
Tener en cuenta que estamos asumiendo que el servidor que procesa el mensaje tiene la capacidad de crear recursos del paciente localmente. De lo contrario, tendremos que crear el paciente como un paso separado como lo hicimos con un servidor de paciente remoto. (Vamos a pensar en el procesamiento de mensajes con más detalle cuando pensamos en el flujo de trabajo en otra publicación)
Provider
La observación tiene un elemento ejecutante que es la persona / dispositivo que realizó la observación. En nuestro caso, este será un proveedor, aunque un dispositivo es otro uso común; pensaremos en las implicaciones de eso en otra publicación.
Las mismas consideraciones se aplicarán al Proveedor como lo hizo para el Paciente en términos de encontrar un recurso y proporcionarlo como una referencia a la Observación, pero hay un par de ganchos adicionales:
Hay más ubicaciones posibles en el mensaje v2 en las que podemos obtener información de "actor", y la que elijamos dependerá del tipo de mensaje (consulte la asignación en la especificación para ver algunas de las posibilidades).
Y dependiendo de cuál escojamos, es probable que tengamos menos información sobre el proveedor en nuestro mensaje, por lo que es más difícil crear uno si aún no existe en nuestro sistema (y la política local lo permite).
En nuestro caso elegiremos OBX-16 - observador responsable. Esto tiene la ventaja añadida de que el tipo de datos v2 para este campo es XCN (número de identificación compuesto extendido y nombre para personas), lo que significa que deberíamos tener los detalles suficientes para crear un recurso de proveedor si es necesario (siempre que todos los campos mensaje están llenos, por supuesto).
Conclusiones
Cuando comencé este ejercicio, asumí que el ejercicio de mapeo sería sencillo, y en un nivel alto, es razonable. Sin embargo, al igual que todas las implementaciones de v2, existe una gran cantidad de opciones para el mapeo, lo que tal vez no sea demasiado sorprendente dada la complejidad de la atención médica. Incluso si los proveedores proporcionan herramientas con asignaciones "estándar" y generación narrativa automatizada, espero que la mayoría de las implementaciones requieran un cierto "ajuste" de esas asignaciones para recursos individuales ...
¡Y muchas de las elecciones hechas en este post ciertamente pueden ser desafiadas!
La cuestión de la "política" surgió un poco: lo que deben hacer los sistemas en determinadas circunstancias, como los nuevos pacientes o en los que hay múltiples pacientes con el mismo identificador o qué hacer cuando no se puede encontrar un proveedor, también es más importante que Yo había anticipado.
Referencias
https://fhirblog.com/2014/10/05/mapping-hl7-version-2-to-fhir-messages/



Comentarios
Publicar un comentario